
RAG vs. Fine-Tuning vs. Prompt Engineering: When to Use What
Table of Contents+
- What Do These Three Approaches Actually Do?
- How Do Cost, Accuracy, and Timeline Compare?
- When Is Prompt Engineering the Right Choice?
- When Does RAG Become Necessary?
- When Does Fine-Tuning Justify the Investment?
- What Does the Decision Framework Look Like?
- How Does the Hybrid Approach Work in Production?
- What Are the Common Mistakes CTOs Make?
- How Should DACH Mid-Market Companies Approach This Decision?
- Frequently Asked Questions
- References
TL;DR
Prompt engineering is your starting point for every AI use case - it ships in hours and costs near zero. Escalate to RAG when you need access to current or proprietary data. Use fine-tuning only when domain-specific behavior cannot be encoded through prompts. The 2026 production standard is a hybrid of all three, allocated by competitive value.
Key Takeaways
- •Start with prompt engineering for every new AI use case. It costs near zero, ships in hours, and resolves 80% of problems without infrastructure. Only escalate to RAG or fine-tuning when you hit a measurable ceiling - not when a vendor tells you to.
- •RAG is the right choice when your application needs access to current, proprietary, or frequently changing data. It reduces hallucinations by 70-90% on factual tasks and keeps your knowledge base up to date without retraining.
- •Fine-tuning delivers 92-97% accuracy on narrow domain tasks but costs 10x to 50x more per experiment than a well-architected RAG system. Reserve it for cases where the model must learn specific behavior, tone, or decision logic that prompting cannot encode.
- •The hybrid approach is the 2026 production standard: fine-tune a small open model for behavior and formatting, layer RAG on top for knowledge retrieval, and use prompt engineering to orchestrate the output. 92% of enterprises reporting positive AI ROI use a combination of approaches.
- •For DACH mid-market companies, the decision sequence matters more than the technology choice. Validate with prompting in week one, add RAG in weeks two through four if data freshness is critical, and consider fine-tuning only after you have 500 or more curated training examples and a clear accuracy gap.
A practical decision framework for choosing between RAG, fine-tuning, and prompt engineering. Includes cost breakdowns, accuracy benchmarks, data requirements, and implementation timelines for mid-market CTOs.
Every mid-market CTO building AI capabilities faces the same question within the first month: should we use RAG, fine-tuning, or prompt engineering? The vendor landscape makes this harder, not easier. RAG vendors say retrieval is the answer. Fine-tuning platforms say custom training is essential. And prompt engineering advocates claim you never need anything else.
The truth is less marketable but more useful: each technique solves a different problem, and the right answer depends on your data, your latency requirements, and your compliance boundaries - not on which vendor gave the best demo.
After deploying all three approaches across dozens of mid-market projects, I have a clear framework for when to use what. This article lays it out with real cost numbers, accuracy benchmarks, and implementation timelines - so you can make this decision based on evidence, not vendor pressure.
What Do These Three Approaches Actually Do?
Before comparing trade-offs, the definitions matter. These are not interchangeable techniques. They operate at different layers of the AI stack and solve fundamentally different problems.

Prompt engineering crafts instructions within the model's context window. You tell the model what to do, how to format its output, what constraints to follow, and what examples to learn from - all within a single request. No infrastructure changes. No model modifications. The model's weights stay untouched.[1]
Retrieval-Augmented Generation (RAG) retrieves relevant documents from an external knowledge base - typically a vector database - and injects them into the model's context before generating a response. The model's weights stay untouched, but it now has access to your proprietary data at inference time. RAG cuts hallucinations on factual tasks by 70-90%.[2]
Fine-tuning modifies the model's internal weights by training it on your domain-specific data. The model learns your terminology, your output formats, your decision patterns. It becomes a specialist. The base model's general knowledge remains, but its behavior shifts toward your domain.[3]
The critical distinction: prompt engineering and RAG change what the model sees. Fine-tuning changes what the model is. This distinction drives every decision in the framework.
See how ebiCore accelerates development.
How Do Cost, Accuracy, and Timeline Compare?
The numbers tell a clearer story than any architectural diagram. Here is what each approach costs, delivers, and requires for a typical mid-market deployment in 2026.

| Factor | Prompt Engineering | RAG | Fine-Tuning |
|---|---|---|---|
| Implementation time | Hours to days | 2-6 weeks | 8-16 weeks |
| Upfront cost | Near zero | EUR 15,000-40,000 | EUR 5,000-60,000+ |
| Monthly operating cost | API fees only (EUR 50-500) | EUR 500-2,000 (vector DB + embeddings) | EUR 1,000-5,000 (inference hosting) |
| Accuracy on domain tasks | 75-85% | 88-94% | 92-97% |
| Data freshness | Static (model training cutoff) | Real-time (retrieval at inference) | Static (last training run) |
| Minimum data required | None | Documents to index | 500-10,000 curated examples |
| Hallucination reduction | Moderate (with good prompts) | 70-90% reduction | Moderate (domain-specific) |
| Team required | Application developer | Backend engineer + ML engineer | ML engineer + data engineer |
| Latency overhead | None | 200-500ms (retrieval step) | None (baked into model) |
The cost gap is significant. Fine-tuning has a total cost of ownership 10x to 50x higher per experiment than a well-architected RAG system.[4] That does not mean fine-tuning is never worth it - but it means the accuracy improvement must justify a dramatically higher investment.
For context: fine-tuning a 7B parameter model using LoRA costs under EUR 500 per training run in 2026, thanks to parameter-efficient methods that reduce GPU requirements by 90%.[5] But full fine-tuning of a 70B model still runs EUR 15,000 to 60,000 in compute per run. And every data update means another training run.
When Is Prompt Engineering the Right Choice?
Prompt engineering is not a stopgap until you build something better. For the majority of enterprise AI use cases, it is the production solution.
Start with prompt engineering when the knowledge base fits within the model's context window. For knowledge bases under 200,000 tokens, full-context prompting is often cheaper and faster than building a RAG pipeline. You load all relevant context directly into the prompt, and the model reasons over it. No vector database. No embedding pipeline. No retrieval latency.
Modern frontier models accept 128,000 to 1,000,000 tokens in a single request. That is 400 to 3,000 pages of text. For internal documentation, product catalogs, or policy manuals that fit within this window, prompting handles it without additional infrastructure.
Prompt engineering also handles behavior control well. Output formatting, tone adjustment, safety guardrails, task-specific instructions - these are prompt engineering problems. If the model knows the answer but delivers it in the wrong format, a better prompt fixes it. You do not need fine-tuning to change how the model speaks. You need a better system prompt.
In my experience, 80% of the AI features we have shipped for mid-market clients started and stayed as prompt engineering solutions. The team that reaches for RAG or fine-tuning on day one is usually solving for complexity, not for the user problem.
Prompt engineering fails when the model does not have access to the information it needs (a RAG problem), when the model cannot learn a domain-specific behavior pattern from examples alone (a fine-tuning problem), or when you need consistent behavior across thousands of edge cases that cannot be encoded in a prompt.
When Does RAG Become Necessary?
RAG solves a problem that neither prompt engineering nor fine-tuning addresses: runtime access to current, company-internal data. If your AI application must answer questions about documents that change weekly, reference proprietary data that was never in the model's training set, or cite specific sources for compliance reasons, RAG is the only scalable path.

The technical architecture is straightforward. Your documents are chunked, embedded into vectors, and stored in a vector database. At inference time, the user's query is embedded, matched against the most relevant document chunks, and those chunks are injected into the model's context alongside the query. The model generates a response grounded in your actual data - not its training memory.[2]
RAG system development costs range from EUR 15,000 to 40,000 for a production pipeline with hybrid search and re-ranking, scaling to EUR 100,000 or more for multi-tenant or agentic RAG architectures.[6] Monthly infrastructure costs for a typical enterprise deployment at 100,000 queries per day run EUR 10,000 to 19,000 - though smart caching and query routing reduce this by 40-46%.
RAG is the right choice when:
- Data changes frequently. Product catalogs, pricing sheets, policy documents, support knowledge bases - anything that updates more often than you would retrain a model.
- Traceability matters. RAG can cite the specific documents it used to generate a response. For compliance, audit trails, or simply building user trust, this is essential.
- The knowledge base exceeds the context window. When your documents surpass 200,000 tokens, loading everything into a single prompt is no longer feasible. RAG retrieves only the relevant portions.
- Hallucination tolerance is low. In customer-facing applications where factual accuracy is non-negotiable - financial advice, medical information, legal guidance - RAG's grounding in source documents reduces fabricated answers by 70-90%.
RAG does not fix bad data. If your documents are contradictory, outdated, or poorly structured, RAG faithfully retrieves that bad information and presents it with confidence. Data quality is the prerequisite, not the output.
When Does Fine-Tuning Justify the Investment?
Fine-tuning is the most powerful technique and the most overused. Vendors push it because it generates recurring revenue - every data update means another training run, another invoice. But the cases where fine-tuning is genuinely the right answer are narrower than the market suggests.
Fine-tuning is justified when the model must learn a specific behavior pattern. Domain-specific terminology that prompting cannot consistently produce, output formats that require structural precision beyond what few-shot examples achieve, or decision logic that operates on implicit knowledge the model does not have and that documents cannot encode.
A concrete example: a mid-market insurance company needed their claims processing model to classify claim types using internal taxonomy that mapped to 47 categories with specific business rules for each. Prompt engineering achieved 78% accuracy. RAG with the taxonomy document achieved 84%. Fine-tuning on 3,000 labeled claims achieved 96%. The 12-percentage-point improvement justified the investment because each misclassification cost an estimated EUR 340 in manual rework.
Fine-tuning also wins on latency. RAG adds 200-500 milliseconds for the retrieval step - acceptable for most applications, but not for autocomplete, live chat suggestions, or real-time code analysis where sub-200-millisecond response times are required.[1] Fine-tuning bakes the knowledge into the model's weights. No retrieval step. No latency overhead.
The cost reality in 2026: parameter-efficient methods like LoRA and QLoRA have reduced fine-tuning costs by an order of magnitude. A 7B model fine-tunes on a single RTX 4090 in an afternoon for under EUR 500. A quantized 7B model that needs 14 GB of memory at full precision fits in 5-6 GB with 4-bit QLoRA.[5] But the data preparation still consumes 60-80% of project time, and every model update requires re-evaluation across your test suite.
Do not fine-tune when prompt engineering achieves acceptable accuracy, when your data changes faster than you can retrain, when you lack 500 or more curated training examples, or when the task is knowledge retrieval rather than behavior modification.
What Does the Decision Framework Look Like?
The decision is not about technology. It is about three concrete questions.[7]
Question 1: How fresh must the data be? If the answer is "real-time" or "updated weekly," RAG is required. Fine-tuning gives you a snapshot of knowledge at training time. Prompt engineering gives you whatever fits in the context window. Only RAG provides dynamic access to current data without retraining.
Question 2: How much latency is acceptable? If your application requires sub-200-millisecond responses, RAG's retrieval step is a constraint. Fine-tuning or prompt engineering delivers faster inference. For most business applications - customer support, document processing, analytics - the 200-500 millisecond RAG overhead is invisible to users.
Question 3: Where does the compliance boundary lie? For DACH enterprises, data residency and GDPR compliance shape the architecture. RAG with a self-hosted vector database keeps data on your infrastructure. Fine-tuning requires sending training data to the model provider (unless you self-host). Prompt engineering sends query data to the API provider at every inference call. Map your data classification tiers to permitted processing methods before choosing a technique.
The progression that works in practice:
- Week 1: Validate with prompt engineering. Build a prototype using a frontier model API with carefully crafted system prompts and few-shot examples. Measure accuracy against your test cases. If it exceeds your threshold, ship it.
- Weeks 2-4: Add RAG if data freshness or knowledge scope is a bottleneck. Index your documents, build the retrieval pipeline, and measure the accuracy improvement. For most knowledge-intensive applications, this is where you stop.
- Weeks 5-12: Consider fine-tuning only if you have a measurable accuracy gap, 500 or more curated training examples, and a business case that justifies the ongoing cost. Fine-tune a small model (7B-14B parameters) using LoRA for maximum cost efficiency.
Our AI framework cuts development time in half
ebiCore is our proprietary agentic AI framework that accelerates innovation and reduces cost.
Start with a Strategy CallHow Does the Hybrid Approach Work in Production?
The most performant production systems in 2026 combine all three techniques, allocated by function. 92% of large companies reporting positive AI ROI use a mix of third-party APIs, fine-tuned models, and proprietary components.[8]
The hybrid architecture works like this:
Fine-tuning handles behavior. A small open model (Llama, Mistral, 7B-14B parameters) is fine-tuned on your domain data to learn your terminology, output formatting, and task-specific decision patterns. This model runs on your infrastructure or a dedicated cloud instance. It understands how to speak your language.
RAG handles knowledge. A vector database stores your current documents, product data, policy manuals, and knowledge base articles. At inference time, relevant context is retrieved and injected into the fine-tuned model's prompt. The model generates responses grounded in up-to-date, cited source material.
Prompt engineering handles orchestration. System prompts define the task structure, output constraints, safety guardrails, and interaction patterns. They coordinate between the fine-tuned model's behavior and the RAG pipeline's knowledge delivery.
This layered approach delivers the best of each technique: fine-tuning's behavioral precision, RAG's data freshness, and prompt engineering's flexibility. It also contains costs - you fine-tune a small, efficient model instead of paying for frontier model inference on every request.
I built this exact stack for a DACH logistics company last quarter. They had a customer-facing portal that needed to answer questions about shipment status, customs regulations, and pricing - all from internal databases that updated hourly. Prompt engineering alone hallucinated customs rules. RAG alone produced technically correct but awkwardly formatted responses. The hybrid - a fine-tuned 7B model for tone and formatting, RAG for customs and shipment data, prompt engineering for safety rails - achieved 94% user satisfaction in the first month of production.
What Are the Common Mistakes CTOs Make?
After working on dozens of these decisions, I see the same five mistakes repeat across organizations.
Mistake 1: Skipping prompt engineering. Teams jump to RAG or fine-tuning before testing whether a well-crafted prompt solves the problem. Prompt engineering resolves 80% of use cases with zero infrastructure investment. Test it first. Always.
Mistake 2: Building RAG for static data. If your knowledge base changes quarterly or less, you do not need a vector database and retrieval pipeline. Load the documents into the context window. RAG infrastructure is justified when data changes weekly or more frequently.
Mistake 3: Fine-tuning with dirty data. Organizations spend EUR 50,000 on fine-tuning before investing EUR 5,000 in data quality. A fine-tuned model trained on inconsistent, mislabeled data produces consistently wrong outputs - with higher confidence than the base model. Data preparation consumes 60-80% of project time for a reason.[4]
Mistake 4: Ignoring the maintenance cost. RAG requires ongoing document indexing, embedding updates, and retrieval quality monitoring. Fine-tuning requires periodic retraining as your domain evolves. Both require evaluation infrastructure to detect accuracy regressions. The build cost is 30-40% of the total cost of ownership. Factor in years two and three before committing.
Mistake 5: Choosing based on vendor recommendations. RAG vendors recommend RAG. Fine-tuning platforms recommend fine-tuning. Neither has an incentive to tell you that prompt engineering is sufficient. Base your decision on measured accuracy against your specific test cases, not on vendor benchmarks run on curated datasets.
How Should DACH Mid-Market Companies Approach This Decision?
DACH mid-market companies face a specific constraint set: GDPR compliance requirements, limited ML engineering teams, and budgets that do not tolerate failed experiments. 72% of DACH enterprises plan to increase AI investment in 2025.[8] The question is not whether to invest, but how to invest without wasting the first two quarters on the wrong approach.
The practical playbook for a DACH mid-market CTO:
Phase 1 (weeks 1-2): Prompt engineering validation. Use Azure OpenAI Service (EU data residency) or Anthropic's API with a GDPR-compliant data processing agreement. Build your prototype with system prompts and few-shot examples. Measure accuracy against 100 test cases from real business scenarios. Cost: under EUR 1,000 total.
Phase 2 (weeks 3-6): RAG pipeline if needed. If prompt engineering hits an accuracy ceiling because the model lacks access to your proprietary data, build a RAG pipeline. Use a self-hosted vector database (Qdrant or Weaviate on your infrastructure) for data residency compliance. Index your documents with a chunking strategy designed for your content type. Cost: EUR 15,000-30,000 development plus EUR 500-1,500 per month infrastructure.
Phase 3 (weeks 7-12): Fine-tuning if justified. If RAG achieves 88-94% accuracy but your use case demands 95% or higher, fine-tune a small open model using LoRA. Self-host the fine-tuned model on your infrastructure to keep training data fully under your control. Cost: EUR 5,000-15,000 for initial training plus EUR 1,000-3,000 per month for hosting.
At each phase, measure accuracy against the same test suite. If the current phase meets your threshold, stop. The companies that deploy AI fastest are the ones that stop escalating when the current approach is good enough.
For the broader strategic context on enterprise AI adoption, see our guide on AI in enterprise software. For the technical integration patterns behind RAG and fine-tuning, read LLM integration patterns for enterprise. And for the build-vs-buy framing that shapes this decision, see the AI build vs. buy decision.
If you are evaluating RAG, fine-tuning, or a hybrid approach for your product and want to skip the trial-and-error phase, explore our AI services. We have deployed all three approaches for DACH mid-market companies and can help you choose the right one in weeks, not quarters.
Frequently Asked Questions
What is the cost difference between RAG and fine-tuning?
RAG systems cost EUR 15,000 to 40,000 for a production pipeline with ongoing infrastructure of EUR 500 to 2,000 per month. Fine-tuning a 7B parameter model with LoRA costs under EUR 500 per training run, but full fine-tuning of larger models ranges from EUR 15,000 to 60,000 in compute per run. The total cost of ownership for fine-tuning is 10x to 50x higher per experiment than RAG.
Can I combine RAG and fine-tuning in the same system?
Yes, and for most enterprise workloads in 2026, you should. The hybrid pattern fine-tunes a small open model for behavior, formatting, and domain vocabulary, then layers RAG on top for knowledge retrieval. This gives you fast, on-brand, citable answers without retraining every time your data changes.
How much training data do I need for fine-tuning?
A minimum of 500 curated input-output examples for meaningful improvement. Production-quality fine-tuning typically requires 1,000 to 10,000 examples. The data must be high quality - inconsistent or mislabeled examples degrade model performance rather than improve it. Data preparation consumes 60 to 80 percent of fine-tuning project time.
When should I skip RAG and go straight to fine-tuning?
When your use case requires the model to learn a specific language pattern, decision style, or output format that cannot be conveyed through prompting or retrieval. Hard latency requirements below 200 milliseconds also favor fine-tuning, since RAG adds retrieval overhead. Autocomplete, live chat suggestions, and real-time code analysis are common examples.
References
- [1] IBM (2025). "RAG vs fine-tuning vs. prompt engineering. ibm.com
- [2] Contextual AI (2025). "RAG vs Fine-Tuning: Comparison Guide for Enterprise AI. contextual.ai
- [3] Spheron (2026). "How to Fine-Tune LLMs in 2026: Costs, GPUs, and Code." spheron.network
- [4] QuantPi (2025). "RAG vs Fine-Tuning vs Prompt Engineering: The Definitive Decisi quantpi.ai
- [5] Runpod (2026). "Fine-Tune LLMs with LoRA and QLoRA: 2026 Guide." runpod.io
- [6] Stratagem Systems (2026). stratagem-systems.com
- [7] Cloudmagazin (2026). "RAG vs. cloudmagazin.com
- [8] NewVantage Partners (2024).
Explore Other Topics
Ready to accelerate with AI?
30-minute call with an engineering lead. No sales pitch - just honest answers about your project.
98% engineer retention · 14-day delivery sprints · No lock-in contracts
Related Reading

AI Development Partners: Boutique vs. Big Consultancy vs. In-House
Big consultancies charge 2-5x more and staff AI projects with juniors. In-house teams cost $1M+ with 38% attrition. Real cost data for choosing your AI partner.
Filip Kralj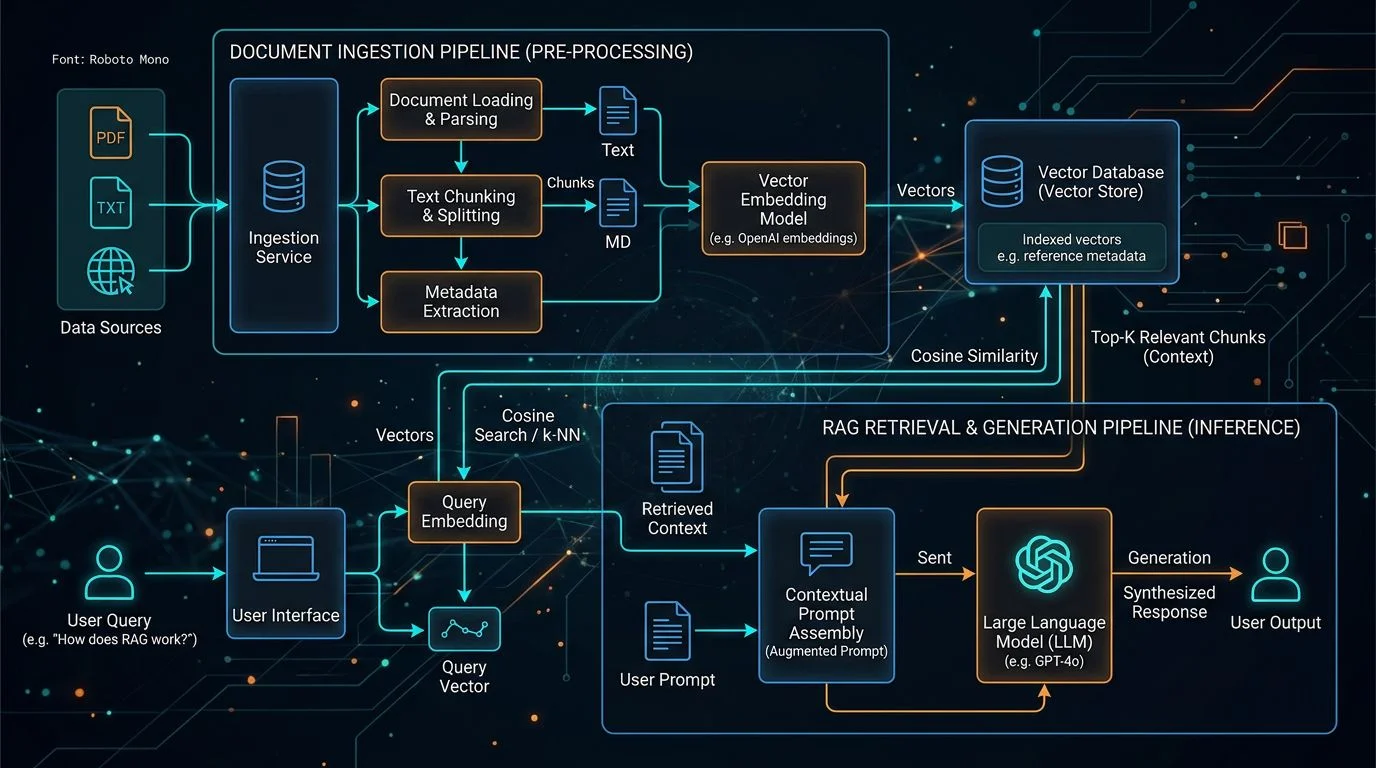
LLM Integration Patterns for Enterprise: RAG, Fine-Tuning, and Agents
51% of enterprises deploying LLMs use RAG. Learn the three production-proven LLM integration patterns - RAG, fine-tuning, and agentic workflows - with architecture decisions, vector database selection, and implementation timelines.
Filip Kralj
From GPT Wrapper to Production AI: The Engineering Gap Nobody Talks About
The engineering gap between a working ChatGPT demo and production-grade AI. Covers latency, error handling, hallucination management, cost optimization, observability, and security for enterprise LLM deployments.
Filip Kralj