The AI Build vs. Buy Decision: Custom Models vs. API Wrappers
Table of Contents+
- The Three Options on the Table
- When Should You Buy (Use APIs)?
- When Should You Build (Custom Models)?
- Why Does Fine-Tuning Exist as a Middle Ground?
- How Real Is the Vendor Lock-In Risk?
- What Are the Data Privacy Implications for DACH Enterprises?
- The Hybrid Strategy That Actually Works
- How Do You Make the Decision for Your Specific Product?
- References
TL;DR
Every enterprise building AI capabilities faces the same fork in the road. On one side: third-party APIs from OpenAI, Anthropic, or Google that ship features in days. On the other: custom models trained on proprietary data that take months to build but give you full control.
Key Takeaways
- •Build custom AI when it is your competitive differentiator - pricing algorithms, proprietary recommendation engines, domain-specific automation. Buy when AI is a utility - code completion, email drafting, generic summarization.
- •LLM inference costs dropped 10x between 2023 and 2024, making API-based integration the default starting point. Running your own model for generic tasks rarely justifies the infrastructure and talent investment.
- •The hybrid approach wins: 92% of large companies reporting positive AI ROI use a mix of third-party APIs, fine-tuned models, and proprietary components - not a single strategy.
- •Vendor lock-in with AI APIs is real but manageable. The average enterprise uses 3.8 LLM providers. Build an abstraction layer from day one so switching providers is a configuration change, not a rewrite.
- •Data privacy is the decision driver for DACH enterprises. Major LLM providers offer EU-hosted inference and data processing agreements, but highly sensitive data still requires on-premise or private cloud deployment.
Custom models cost $100M+ to train from scratch. API wrappers ship in days. Learn when to build, buy, or combine - with cost comparisons, data privacy implications, and vendor lock-in strategies for enterprise AI.
Every enterprise building AI capabilities faces the same fork in the road. On one side: third-party APIs from OpenAI, Anthropic, or Google that ship features in days. On the other: custom models trained on proprietary data that take months to build but give you full control.
In between: fine-tuning, open-source models, and hybrid approaches that combine the speed of APIs with the precision of custom training.
The decision is not binary, and the right answer depends on your competitive position, your data, your regulatory environment, and your team - not on what a vendor demo showed you last quarter.
This article lays out the real cost structures, the data privacy implications, the vendor lock-in risks, and the hybrid strategies that work for mid-sized enterprises navigating this decision.
The Three Options on the Table
Before comparing costs and trade-offs, it helps to define the three distinct approaches enterprises use to build AI capabilities.
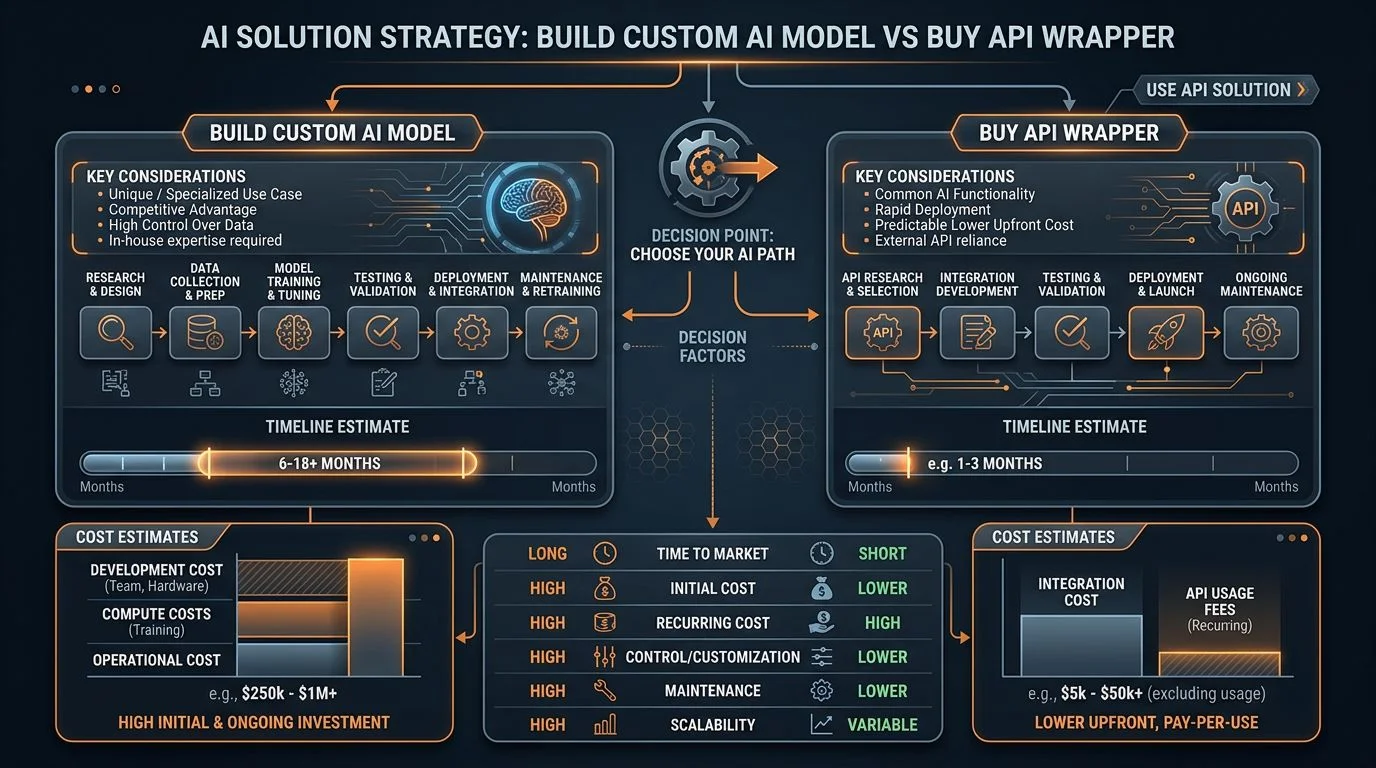
Option 1: API wrappers. You call a third-party LLM (GPT-4, Claude, Gemini) through its API, wrap the call in your application logic, and build product features on top of the responses. You own none of the model infrastructure. You pay per token. You ship in days.
One-third of organizations already use generative AI regularly in at least one business function this way [1].
Option 1: API wrappers
Option 2: Fine-tuning. You take a pre-trained model and further train it on your domain-specific data. The base model's general knowledge stays intact, but its outputs become tuned to your terminology, formatting requirements, and task-specific accuracy needs.
You need curated training data, compute budget, and a team that understands model evaluation. Time to production: 8-16 weeks.
Option 3: Training from scratch. You build and train your own model on proprietary data. This gives you maximum control over model behavior, data handling, and competitive differentiation. It also costs orders of magnitude more. GPT-4's training cost an estimated $100 million [2].
Even smaller domain-specific models cost $500K-5M to train, require dedicated ML engineering teams, and take 6-18 months to reach production quality.
| Factor | API Wrappers | Fine-Tuning | Training From Scratch |
|---|---|---|---|
| Time to production | 1-4 weeks | 8-16 weeks | 6-18 months |
| Upfront cost | Near zero | $10K-100K | $500K-5M+ |
| Ongoing cost model | Per-token API fees | Inference hosting + API fees | Full infrastructure + team |
| Data privacy | Data sent to third-party API | Training data stays local; inference varies | Full control |
| Accuracy on domain tasks | Good (with prompt engineering) | Very good (20-40% improvement) | Best (if data quality is high) |
| Vendor lock-in risk | High (without abstraction layer) | Medium | None |
| Team required | Application developers | ML engineers + app developers | Full ML team (5-10 specialists) |
See how ebiCore accelerates development.
When Should You Buy (Use APIs)?
The default answer for most AI features in most products is: use APIs. The economics are clear, and the capabilities are sufficient for the majority of enterprise use cases.

LLM inference costs dropped 10x between March 2023 and March 2024. The cost of generating a 1,000-word response from a state-of-the-art model went from $0.50 to $0.05 - and smaller models push that to $0.005.
At these prices, building your own inference infrastructure for generic tasks is like building your own email server in 2026. You can. You should not.
API wrappers are the right choice when the AI capability is not your competitive differentiator. Content summarization, email drafting, customer support chatbots, internal knowledge retrieval, code completion - these are commodity AI features. Your product differentiates on the business logic around the AI output, not on the model generating it.
Gartner predicts that by 2026, 80% of enterprises will have used generative AI APIs or deployed generative AI-enabled applications [3]. The market has already decided: APIs are the default integration pattern. The question is not whether to use them, but how to use them without creating dependencies you cannot manage.
"The fastest path to AI ROI is not building a model. It is wrapping an API call in good product design. Ship the feature in 2 weeks, measure the impact, then decide if custom training is worth the investment."
When Should You Build (Custom Models)?
Custom model development is justified when AI is your competitive moat - when the model's behavior directly determines whether customers choose your product over alternatives.
Proprietary data as a moat. If your organization has accumulated domain-specific data that competitors cannot replicate - years of industry transactions, specialized measurements, unique user behavior patterns - a custom model trained on that data creates a defensible advantage.
The model's outputs improve with more data, and your data advantage widens over time. Global corporate AI investment reached $189.6 billion in 2023, nearly 8x the 2017 level [4] - much of that investment targets proprietary data advantages.
Proprietary data as a moat
Regulatory requirements. Some industries - healthcare, defense, financial services - require that AI models never send data to third-party infrastructure. For these use cases, on-premise deployment of open-source models (Llama, Mistral, Falcon) or custom-trained models is not optional.
The EU AI Act requires strict transparency and safety requirements for high-risk AI systems by 2025-2026 [5]. In these contexts, full model control is a compliance requirement, not a preference.
Task-specific accuracy requirements. When prompt engineering and fine-tuning cannot achieve the accuracy threshold your use case demands - medical diagnosis support, legal document analysis, safety-critical systems - custom training on curated domain data is the path to production-grade accuracy.
But 67% of enterprises cite data quality as the number-one barrier to AI adoption [6]. Custom model training amplifies data quality problems - if your training data is inconsistent, your custom model will be consistently wrong.
The talent requirement is the practical constraint. The AI talent gap is significant: there are 2x more AI job postings than qualified candidates, and the average time to fill an AI/ML role is 68 days [7]. Building an in-house ML team takes 6-12 months before the first model reaches production.
For most mid-sized enterprises, this timeline does not align with competitive pressure.

Why Does Fine-Tuning Exist as a Middle Ground?
Fine-tuning splits the difference between API wrappers and custom training. You get domain-specific accuracy improvements without the cost and complexity of training from scratch.

The mechanism is straightforward: take a pre-trained model (GPT-4, Claude, Llama), provide it with hundreds or thousands of examples of your specific task - input-output pairs that demonstrate the behavior you want - and run additional training iterations. The model retains its general language understanding and gains your domain specialization.
Fine-tuning improves task accuracy by 20-40% compared to prompt engineering alone. For a product classification system, that might mean going from 85% accuracy with prompt engineering to 95% accuracy with fine-tuning. For a document extraction pipeline, it might mean consistent output formatting that prompt engineering cannot reliably achieve.
The cost profile is manageable. Fine-tuning a model on 10,000 examples costs $50-500 depending on the model and provider. Inference costs are comparable to or slightly higher than the base model.
The team requirement is an ML engineer who understands data preparation, model evaluation, and the fine-tuning APIs - not a full research team.
Fine-tuning makes sense when you have hit the ceiling of what prompt engineering can deliver, when you need consistent output formatting or domain terminology, when your task has clear right/wrong answers that can be captured in training examples, and when the accuracy improvement justifies the ongoing retraining cost as your domain evolves.
It does not make sense when your use case works well enough with prompt engineering (the 80/20 rule applies), when you lack curated training data, or when the task changes frequently enough that retraining becomes a continuous overhead.
How Real Is the Vendor Lock-In Risk?
The fear of vendor lock-in with AI APIs is valid but often overstated. The practical risk depends on how you architect the integration, not on whether you use third-party APIs at all.
The average enterprise uses 3.8 different LLM providers. This multi-model approach is intentional - different models excel at different tasks, and provider diversification reduces concentration risk. If OpenAI changes pricing, you route traffic to Anthropic. If a new model outperforms both, you add it to the rotation.
The architectural pattern that prevents lock-in is an abstraction layer between your application code and the AI provider. Your application code calls a standardized internal AI service. That service translates the request to the provider-specific format, sends it, and normalizes the response.
Switching providers means changing the adapter in the service layer, not rewriting application code.
Where lock-in becomes a real problem:
- Provider-specific features. If you build heavily on OpenAI's function calling, Anthropic's tool use, or Google's grounding APIs, your prompts and integration logic become provider-specific. Use common patterns across providers to minimize this.
- Fine-tuned models. A model fine-tuned on OpenAI's GPT-4 cannot be migrated to Anthropic's Claude. If you fine-tune, maintain your training data and evaluation benchmarks so you can re-fine-tune on a different base model.
- Embedding lock-in. Vector databases store embeddings generated by a specific model. Switching embedding models means re-embedding your entire corpus. This is operationally expensive but technically straightforward. Plan for it by keeping your raw data pipeline intact.
The pragmatic approach: start with one provider, build the abstraction layer from day one, and add a second provider within the first quarter. The cost of the abstraction layer is a few days of engineering.
The cost of not having it is weeks of rework when you inevitably need to switch or add providers.
Our AI framework cuts development time in half
ebiCore is our proprietary agentic AI framework that accelerates innovation and reduces cost.
Start with a Strategy CallWhat Are the Data Privacy Implications for DACH Enterprises?
For enterprises operating in Germany, Austria, and Switzerland, data privacy is not a nice-to-have consideration - it is the decision driver that shapes the entire AI architecture.
Major LLM providers offer enterprise tiers with clear data handling guarantees. OpenAI's Enterprise tier and Anthropic's API both guarantee that customer data is not used for model training. Data is processed at inference time and discarded. Both offer data processing agreements (DPAs) compatible with GDPR.
Azure OpenAI Service and Google Vertex AI offer EU data residency - inference runs on EU-based servers, and data never leaves the region.
For most enterprise use cases - customer support, internal knowledge retrieval, content generation - these guarantees are sufficient. The data being processed is operational (user queries, document content, support tickets), and the DPAs cover the processing requirements.
The calculus changes for highly sensitive data categories. Patient health records, financial transactions, classified government data, or trade secrets may require that no data leaves your infrastructure. In these cases, the architecture shifts to:
- Open-source models on private infrastructure. Deploy Llama 3, Mistral, or similar models on your own GPU infrastructure or private cloud. No data leaves your network. The trade-off is operational complexity - you manage inference scaling, model updates, and GPU provisioning.
- On-premise AI appliances. NVIDIA, Dell, and others offer pre-configured AI inference servers that run models locally. Higher upfront cost, zero data leakage risk.
56% of enterprises lack a formal AI governance framework [8]. For DACH enterprises evaluating the build-vs-buy decision, the governance framework should be the first deliverable - before the first API call or model training run. Define data classification tiers, map each tier to permitted processing methods, and document the decision.
This takes days and prevents months of compliance remediation.
The Hybrid Strategy That Actually Works
The most effective AI strategy is not build or buy. It is build and buy, allocated by competitive value.
92% of large companies report positive AI ROI [9]. The companies driving that statistic use a hybrid approach:
Buy (APIs) for commodity capabilities
Buy (APIs) for commodity capabilities. Code completion, email drafting, meeting summarization, generic customer support, internal knowledge search. These features do not differentiate your product. Ship them fast using third-party APIs and invest your engineering time where it creates competitive value.
Fine-tune for domain accuracy. When prompt engineering hits its ceiling - inconsistent formatting, domain terminology gaps, task-specific accuracy below your threshold - fine-tune. Keep the training data pipeline clean so you can switch base models as the market evolves.
Fine-tune for domain accuracy
Build for competitive differentiation. If your AI model's behavior is the reason customers choose your product, own the model. This means proprietary training data, in-house ML engineering, and a commitment to continuous improvement. But verify that the differentiation is real and measurable before committing to the build path.
Partner for production-grade integration. Most mid-sized enterprises have domain expertise and data but lack the ML engineering team to build and maintain AI infrastructure. A development team with AI framework expertise - like easy.bi with ebiCore, our proprietary agentic AI-based development framework - bridges that gap.
You get production-grade AI delivered in 14-day sprint cycles without the 12-18 month ramp-up of building an internal AI team.
The allocation framework is simple: if a competitor could build the same AI feature using the same public APIs and the same public data, do not build it - buy it. If your data or domain expertise creates output that competitors cannot replicate, build it (or fine-tune it).
If you need production-grade AI integration but lack the team, find a custom solutions partner who has done it before.
How Do You Make the Decision for Your Specific Product?
The build-vs-buy decision comes down to four questions. Answer them honestly, and the right approach becomes clear.
Question 1: Is AI output your competitive differentiator? If yes - if the quality of AI-generated recommendations, predictions, or analysis is why customers choose you - then you need to own the model. Fine-tune at minimum. Consider custom training if you have proprietary data.
If no - if AI augments a product that differentiates on other dimensions - use APIs.
Question 1: Is AI output your competitive differentiator
Question 2: Do you have the data? Custom models and fine-tuning require curated, labeled training data. Organizations spend 45% of their AI project time on data preparation [6]. If your data is inconsistent, duplicated, or undocumented, fix the data before investing in custom models.
A state-of-the-art model on dirty data produces state-of-the-art garbage.
Question 3: Do you have the team? Custom model development requires ML engineers, data scientists, and MLOps specialists. Organizations with mature MLOps practices deploy models 5x faster and with 30% fewer production incidents [10]. If you do not have this maturity, building an internal team takes 6-12 months.
The partner model delivers production AI faster.
Question 2: Do you have the data
Question 4: What are your data residency requirements? If GDPR-compliant API processing is sufficient for your data categories, APIs with EU-hosted inference solve the privacy question.
If regulatory or contractual requirements demand that data never leaves your infrastructure, you need on-premise deployment - which constrains you to open-source or custom models.
Most enterprises answer "no" to Question 1 for the majority of their AI use cases. That means most AI features should start as API integrations, graduate to fine-tuning only when accuracy demands it, and reserve custom training for the rare cases where AI output is the product itself.
For the broader strategic context on enterprise AI adoption - including governance frameworks and implementation timelines - see our comprehensive guide: AI in Enterprise Software: What's Real, What's Hype, and What to Build First.
For teams evaluating how to add AI to an existing product without rebuilding, read Building AI Features Into Existing Products (Without Starting Over). And for the technical patterns behind LLM integration - RAG, fine-tuning, and agentic workflows - see LLM Integration Patterns for Enterprise: RAG, Fine-Tuning, and Agents.
References
- [1] McKinsey, 2024 - One-third of organizations use generative AI regularly in at le
- [2] Stanford HAI, 2024 - GPT-4 training cost an estimated $100 million; training cos
- [3] Gartner, 2023 - By 2026, 80% of enterprises will have used generative AI APIs or
- [4] Stanford HAI, 2024 - Global corporate AI investment reached $189.
- [5] European Commission, 2024 - EU AI Act requires high-risk AI systems to meet stri
- [6] Deloitte, 2023 - Data quality is the #1 barrier to AI adoption, cited by 67% of
- [7] LinkedIn, 2023 - 2x more AI job postings than qualified candidates; average 68 d
- [8] Deloitte, 2023 - 56% of enterprises lack a formal AI governance framework.
- [9] NewVantage Partners, 2024 - 92% of large companies report positive AI ROI; media
- [10] Algorithmia / DataRobot, 2023 - Mature MLOps practices: 5x faster model deployme
Explore Other Topics
Ready to accelerate with AI?
30-minute call with an engineering lead. No sales pitch - just honest answers about your project.
98% engineer retention · 14-day delivery sprints · No lock-in contracts
Related Reading

Build vs Buy Your E-Commerce Platform: The EUR Decision Framework
80% of mid-market retailers should buy. Use this EUR decision framework with real cost comparisons, scoring criteria, and case examples to make the right call.
Andrej Lovsin
The Build vs. Buy Decision: How to Staff Enterprise Software Projects in 2026
The build vs. buy decision in 2026 depends on talent availability, team structure, and outcome accountability. Compare in-house, nearshore, and offshore models with DACH market data and a practical decision framework.
Andrej Lovsin
AI in Enterprise Software: What's Real, What's Hype, and What to Build First
55% of enterprises adopted AI, but only 22% get past pilot. Learn which LLM patterns, governance frameworks, and first-90-day strategies deliver real ROI.
Filip Kralj