LLM Integration Patterns for Enterprise: RAG, Fine-Tuning, and Agents
Table of Contents+
- Why Integration Pattern Selection Matters More Than Model Selection
- Pattern 1: Retrieval-Augmented Generation (RAG)
- Choosing the Right Vector Database
- Pattern 2: Fine-Tuning for Domain Accuracy
- Pattern 3: Agentic Workflows
- How Do These Patterns Combine in Practice?
- What Does a Production RAG Architecture Look Like?
- The Implementation Roadmap
- References
TL;DR
Integrating an LLM into an enterprise product is not a single technical decision. It is a series of architectural choices that determine whether your AI feature hallucinates, scales, complies with regulation, and delivers measurable value - or whether it becomes another pilot that never reaches production.
Key Takeaways
- •RAG is the default LLM integration pattern for enterprise: 51% of enterprises deploying LLMs use it, and it reduces hallucinations by 40-60% by grounding model outputs in your actual data.
- •Fine-tuning improves task accuracy by 20-40% over prompt engineering but requires curated training data and ongoing retraining - only pursue it after RAG has proven the use case has real demand.
- •Agentic patterns go beyond single-prompt interactions: agents plan multi-step workflows, call external tools, and iterate autonomously. ebiCore uses this pattern to orchestrate code generation, testing, and deployment across the full development lifecycle.
- •Vector database selection depends on scale: pgvector for teams already on PostgreSQL, Pinecone or Weaviate for dedicated vector workloads, and Qdrant for on-premise deployments with strict data residency requirements.
- •The integration sequence matters: start with prompt engineering and function calling (1-4 weeks), add RAG for knowledge grounding (4-8 weeks), fine-tune only when accuracy demands it (8-16 weeks), and introduce agentic workflows for complex multi-step processes.
51% of enterprises deploying LLMs use RAG. Learn the three production-proven LLM integration patterns - RAG, fine-tuning, and agentic workflows - with architecture decisions, vector database selection, and implementation timelines.
Integrating an LLM into an enterprise product is not a single technical decision. It is a series of architectural choices that determine whether your AI feature hallucinates, scales, complies with regulation, and delivers measurable value - or whether it becomes another pilot that never reaches production.
Only 22% of AI projects make it from pilot to production [1]. The ones that succeed share a pattern: they choose the right integration architecture for their specific use case, not the most impressive one they saw in a demo.
This article breaks down the three production-proven LLM integration patterns - Retrieval-Augmented Generation (RAG), fine-tuning, and agentic workflows - with the architecture decisions, infrastructure requirements, and implementation timelines that determine success or failure.
Why Integration Pattern Selection Matters More Than Model Selection
Teams spend weeks evaluating GPT-4 vs. Claude vs. Gemini vs. Llama. They spend days - or hours - deciding how to integrate the chosen model into their product. This is backwards.
The integration pattern determines how accurate the outputs are, how the system handles your proprietary data, how it scales under load, and how it complies with data residency requirements. The model is a component within the pattern. Swapping models is a configuration change. Swapping integration patterns is an architecture rewrite.
55% of organizations have adopted AI in at least one business function [2]. But the gap between adoption and production value remains wide because most organizations adopt a model without adopting an integration strategy.
They call an API, get a response, and ship it to users - with no retrieval grounding, no evaluation pipeline, and no fallback mechanism. The result is inconsistent outputs, hallucinated facts, and user trust erosion that takes months to repair.
The three patterns described below operate at different levels of complexity and investment. Each solves a specific class of problems. Choosing the wrong one wastes months. Choosing the right one compresses time-to-production from quarters to weeks.
See how ebiCore accelerates development.
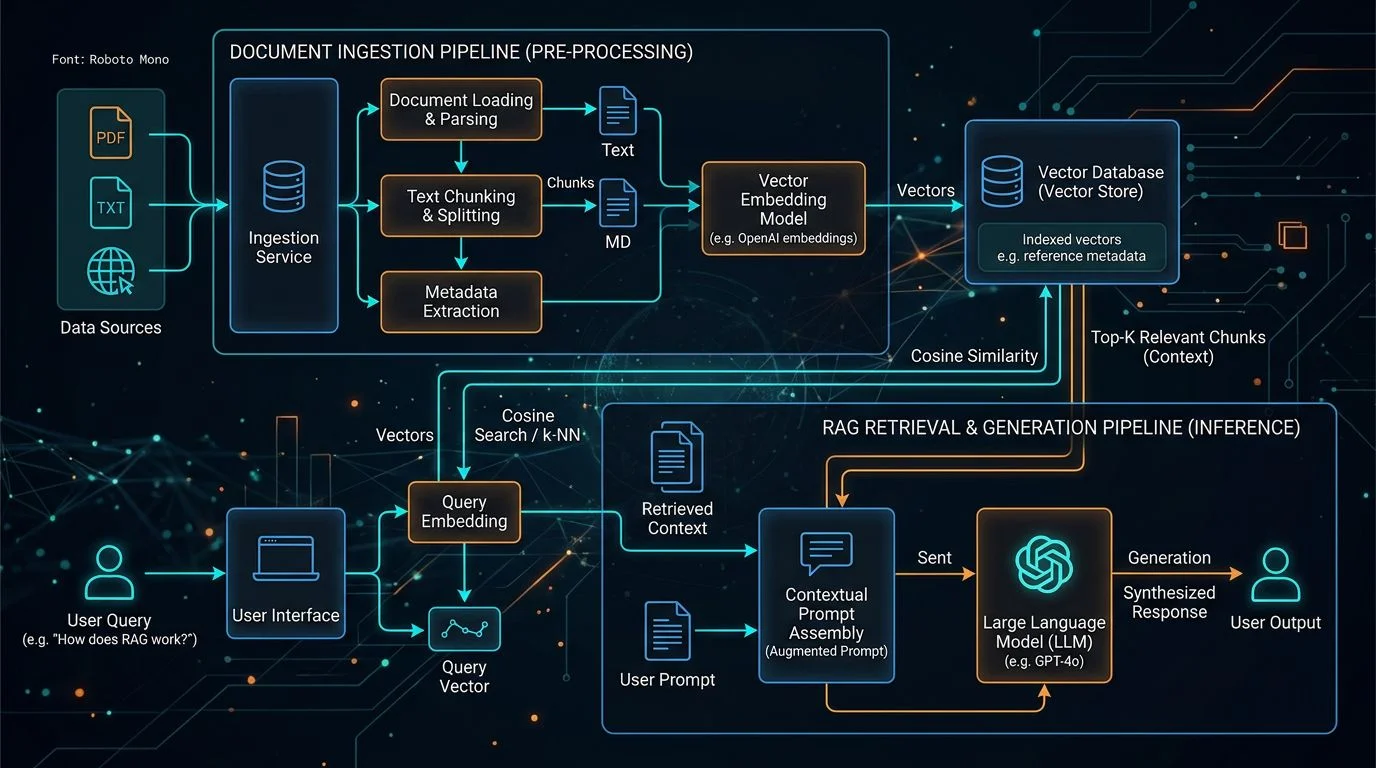
Pattern 1: Retrieval-Augmented Generation (RAG)
RAG is the most widely deployed LLM pattern in enterprise. 51% of enterprises deploying LLMs use it [3]. The reason: it solves the two biggest problems with base LLMs - hallucination and staleness - without requiring any model training.

The architecture has three components. A retrieval layer converts your enterprise data (documents, knowledge bases, database content) into vector embeddings stored in a vector database.
At query time, the user's question is converted to an embedding, the most semantically similar documents are retrieved, and those documents are passed to the LLM as context alongside the question. The LLM generates a response grounded in your actual data rather than its training data.
When to use RAG
RAG reduces hallucinations by 40-60% compared to using a base LLM alone [4]. This reduction is the primary reason enterprises adopt it: a customer-facing AI assistant that invents product features or misquotes policies creates liability. RAG constrains the model's outputs to information that exists in your verified data.
When to use RAG: Internal knowledge retrieval, customer support Q&A, product documentation search, legal and compliance document analysis, technical support automation. Any use case where the model needs to reference your specific data rather than general knowledge.
Architecture decisions
Architecture decisions:
- Chunking strategy. How you split documents into chunks determines retrieval quality. Too large (2,000+ tokens) and the LLM gets noisy context. Too small (100 tokens) and the LLM loses meaning. The sweet spot is 300-500 tokens with 50-100 token overlap between chunks for most enterprise content.
- Embedding model selection. OpenAI's text-embedding-3-large, Cohere's embed-v3, and open-source alternatives like BGE or E5 all produce high-quality embeddings. The choice depends on cost, latency requirements, and whether you can send data to a third-party API.
- Retrieval strategy. Semantic search alone misses keyword-exact matches. Hybrid retrieval - combining semantic similarity scores with traditional keyword (BM25) scores - outperforms either approach alone by 10-15% on enterprise document corpora.
- Context window management. With 128K+ context windows available on modern models, it is tempting to stuff everything retrieved into the prompt. This increases cost and degrades quality. Retrieve 5-10 relevant chunks. If the answer is not in those chunks, the question needs reformulation, not more context.
"RAG does not make the model smarter. It makes the model informed. The difference between a hallucinating chatbot and a reliable enterprise AI assistant is not the model - it is the retrieval pipeline that feeds it verified data."
Choosing the Right Vector Database
Vector database adoption grew 300% year-over-year in 2023, driven by enterprise RAG implementations [5]. The market has fragmented into specialized options, and the right choice depends on your existing infrastructure, scale requirements, and data residency constraints.
| Vector Database | Best For | Hosting | Scalability | Key Consideration |
|---|---|---|---|---|
| pgvector | Teams on PostgreSQL | Self-hosted / managed PG | Good (millions of vectors) | No new infrastructure; limited at 100M+ vectors |
| Pinecone | Fully managed vector workloads | Cloud only | Excellent (billions) | Lowest operational overhead; data leaves your infra |
| Weaviate | Hybrid search (vector + keyword) | Cloud or self-hosted | Excellent | Built-in hybrid retrieval; strong developer experience |
| Qdrant | On-premise / data residency | Self-hosted or cloud | Very good | Rust-based, performant; full control deployment |
| Milvus | Large-scale ML workloads | Self-hosted or Zilliz Cloud | Excellent (billions+) | Apache 2.0 license; steep learning curve |
| ChromaDB | Prototyping and small corpora | Embedded / self-hosted | Limited | Fastest to start; not for production scale |
For most DACH enterprises starting with RAG, the decision is straightforward. If you run PostgreSQL, start with pgvector - no new infrastructure, no new vendor relationship. If your corpus exceeds 10 million vectors or you need sub-10ms retrieval latency, move to a dedicated vector database.
If data residency requires that embeddings stay on your infrastructure, Qdrant or self-hosted Weaviate are the options.

Pattern 2: Fine-Tuning for Domain Accuracy
When RAG and prompt engineering cannot achieve the accuracy or consistency your use case demands, fine-tuning is the next step. Fine-tuning takes a pre-trained model and runs additional training iterations on your domain-specific data - typically hundreds to thousands of input-output pairs that demonstrate the exact behavior you want.

Fine-tuning improves task accuracy by 20-40% compared to prompt engineering alone. The improvement comes from three sources: the model learns your domain terminology and uses it consistently, the model internalizes your output format requirements, and the model develops a bias toward your domain's patterns rather than general web text.
When to fine-tune
When to fine-tune: When prompt engineering achieves 80% accuracy but you need 95%. When the LLM inconsistently formats outputs despite detailed instructions. When you need domain-specific terminology that the base model frequently gets wrong. When your use case has clear, evaluable right/wrong answers that can be captured in training examples.
When not to fine-tune: When your requirements change frequently (retraining is expensive). When you lack curated training data (garbage in, garbage out applies doubly to fine-tuning). When prompt engineering already meets your accuracy bar - fine-tuning for marginal improvement rarely justifies the cost.
When not to fine-tune
The fine-tuning workflow:
- Curate training data. Collect 500-5,000 input-output pairs that represent your target behavior. Quality matters more than quantity. 500 high-quality examples outperform 5,000 noisy ones.
- Establish evaluation benchmarks. Before fine-tuning, measure the base model's accuracy on a held-out test set. This is your baseline. Without it, you cannot prove the fine-tuning improved anything.
- Train and evaluate. Run fine-tuning on your chosen provider (OpenAI, Anthropic, or a self-hosted base model like Llama). Evaluate against your benchmark. If accuracy did not improve meaningfully, the problem is data quality, not model capability.
- Deploy with monitoring. Fine-tuned models can drift as your domain evolves. Monitor output quality in production. Plan for quarterly retraining with updated training data.
Organizations spend 45% of their AI project time on data preparation [6]. For fine-tuning, this percentage is higher. The training data curation step is where most fine-tuning projects succeed or fail - not in the model training itself.
Pattern 3: Agentic Workflows
Agentic AI extends LLM integration from single-prompt interactions to autonomous multi-step workflows. Instead of answering a question, an agent plans a sequence of actions, executes them using external tools (APIs, databases, file systems), evaluates intermediate results, and adapts its approach until the task is complete.
Agentic AI frameworks saw 10x growth in GitHub stars from Q1 2023 to Q1 2024 [7]. Production adoption is early but accelerating - 8% of enterprises have agentic AI in production, and 42% are actively experimenting.
Planner
The architecture of an agentic workflow includes:
- Planner. Given a goal, the agent decomposes it into subtasks and determines the execution order. For a complex data migration task, the planner identifies tables, dependencies, transformation rules, and validation steps.
- Tool layer. The agent calls external systems - database queries, API endpoints, file operations, CI/CD pipelines. This is what separates agents from chatbots: they act on real systems, not just generate text.
- Memory. The agent maintains state across steps and sessions. It remembers what worked in previous tasks, what architectural patterns the project uses, and what constraints apply. Each task builds on accumulated context.
- Evaluator. After each step, the agent assesses whether the output meets the task requirements. If a generated test fails, the agent reads the error, adjusts, and retries. This feedback loop is the core of agentic behavior.
At easy.bi, ebiCore - our proprietary agentic AI-based SaaS development framework on enterprise high-availability architecture - orchestrates agents across the full software development lifecycle. Code scaffolding, test generation, code review triage, and deployment configuration are coordinated by agents that share project context and learn from each sprint.
No competitor in the DACH nearshore space has an equivalent AI-powered development framework.
When to use agentic patterns: Multi-step business processes (order fulfillment, document processing pipelines, automated reporting). Complex development workflows (code generation + testing + review + deployment). Any task that currently requires a human to chain together 5+ tools or systems in a sequence.
For a detailed guide on agentic frameworks and how ebiCore applies them, see our spoke article on agentic AI frameworks.
Our AI framework cuts development time in half
ebiCore is our proprietary agentic AI framework that accelerates innovation and reduces cost.
Start with a Strategy CallHow Do These Patterns Combine in Practice?
Production enterprise AI systems rarely use a single pattern in isolation. The most effective architectures layer patterns to get the benefits of each.
RAG + agentic workflow. The agent receives a complex question, breaks it into sub-queries, retrieves relevant documents for each sub-query using RAG, synthesizes the results, and generates a comprehensive response. This outperforms a single RAG query on complex questions that span multiple document domains.
Fine-tuned model + RAG. The fine-tuned model handles domain-specific language and formatting. RAG provides the factual grounding. The combination delivers both accuracy and factual reliability - the fine-tuned model knows how to express the answer, and RAG ensures the answer contains verified information.
Agentic workflow + function calling. The agent uses function calling to interact with external systems (CRM queries, database updates, API calls) as part of its multi-step execution. This is how enterprise automation agents coordinate actions across ERP, CRM, and warehouse management systems.
The implementation sequence mirrors the complexity: start with prompt engineering and function calling for simple tasks, add RAG when the model needs access to your data, fine-tune when domain accuracy matters, and introduce agentic workflows when the task requires multi-step autonomy.
What Does a Production RAG Architecture Look Like?
A production-grade RAG system for enterprise use extends well beyond the basic "embed, retrieve, generate" loop. The components that separate a demo from a production system are the ones teams skip in the prototype.
Data ingestion pipeline. Documents flow continuously from source systems (SharePoint, Confluence, databases, CMS) into the embedding pipeline. This pipeline handles format conversion, metadata extraction, chunking, embedding, and vector storage. It runs on a schedule or triggered by document updates. Without automated ingestion, your knowledge base becomes stale within weeks.
Data ingestion pipeline
Query preprocessing. Raw user queries often need reformulation before retrieval. A query like "what's our return policy for damaged items bought last month" contains a factual question (return policy) and temporal context (last month) that should be handled differently.
Query expansion, temporal filtering, and intent classification improve retrieval accuracy by 15-25%.
Response generation with citations. The generated response must cite the source documents. Users need to verify AI outputs against the original source - especially in regulated industries.
Citation generation is an architecture requirement, not a nice-to-have. 44% of organizations have experienced cost reductions from AI implementation in business units where AI is deployed [8] - but these gains depend on users trusting the outputs enough to act on them.
Query preprocessing
Evaluation pipeline. How do you know if your RAG system is returning accurate answers? Automated evaluation compares generated responses against ground-truth answers for a curated test set. This pipeline runs after every change to the chunking strategy, embedding model, or retrieval parameters. Without it, you are shipping changes blind.
Monitoring and observability. Track retrieval quality (are the right documents being retrieved?), generation quality (is the model using the retrieved context accurately?), latency (is the system fast enough for interactive use?), and cost (are you over-retrieving or over-generating?). These metrics surface degradation before users report it.
The Implementation Roadmap
The path from no LLM integration to a production-grade enterprise system follows a clear sequence. Each stage is independently valuable and builds the foundation for the next.
Stage 1: Prompt engineering + function calling (Week 1-4). Integrate an LLM API for classification, extraction, or generation tasks. Use function calling to connect the model to existing APIs. Ship a feature. This stage validates the use case with minimal investment.
Stage 1: Prompt engineering + function calling (Week 1-4)
Stage 2: RAG for knowledge grounding (Week 5-12). Add a vector database, build an embedding pipeline for your enterprise data, and implement hybrid retrieval. This stage transforms generic LLM outputs into responses grounded in your specific knowledge.
RAG is where most enterprise AI deployments reach their sweet spot of value vs. complexity.
Stage 3: Fine-tuning for domain accuracy (Week 13-24). If Stage 2 outputs need higher accuracy or more consistent formatting, curate training data and fine-tune. Measure accuracy improvement against your evaluation benchmark before shipping to production.
Stage 2: RAG for knowledge grounding (Week 5-12)
Stage 4: Agentic workflows (Week 25+). For complex multi-step processes, build agentic pipelines that coordinate multiple AI calls with tool use, memory, and evaluation loops. This stage requires the foundation from previous stages - agents need RAG for knowledge access and fine-tuned models for domain accuracy.
Organizations with mature MLOps practices deploy models 5x faster and with 30% fewer production incidents [9]. The roadmap above builds that maturity incrementally - you do not need a full MLOps platform on day one.
You need a solid API integration, a working evaluation pipeline, and the discipline to measure before scaling.
For the broader strategic context on enterprise AI - from adoption reality to governance frameworks - see our pillar guide: AI in Enterprise Software: What's Real, What's Hype, and What to Build First.
For the build-vs-buy decision that shapes which patterns you own versus outsource, read The AI Build vs. Buy Decision: Custom Models vs. API Wrappers.
And for teams ready to integrate AI into existing products using these patterns, our custom solutions team ships production RAG and agentic systems in 14-day sprint cycles.
References
- [1] Gartner, 2023 - Only 22% of data science and AI projects make it from pilot to p
- [2] McKinsey, 2023 - 55% of organizations have adopted AI in at least one business f
- [3] Databricks, 2024 - RAG is used by 51% of enterprises deploying LLMs.
- [4] Vectara, 2024 - RAG reduces hallucinations by 40-60% compared to base LLM alone.
- [5] DB-Engines, 2024 - Vector database adoption grew 300% year-over-year in 2023.
- [6] Deloitte, 2023 - Organizations spend 45% of their AI project time on data prepar
- [7] GitHub, 2024 - Agentic AI frameworks saw 10x growth in GitHub stars from Q1 2023
- [8] McKinsey, 2023 - 44% of organizations have experienced cost reductions from AI i
- [9] Algorithmia / DataRobot, 2023 - Mature MLOps practices: 5x faster model deployme
Explore Other Topics
Ready to accelerate with AI?
30-minute call with an engineering lead. No sales pitch - just honest answers about your project.
98% engineer retention · 14-day delivery sprints · No lock-in contracts
Related Reading

How AI Is Reshaping Enterprise Software Development
AI is changing how enterprise software gets built. Learn how agentic frameworks, automated QA, and AI-assisted architecture are cutting development timelines by 40%.
Filip Kralj
AI in Enterprise Software: What's Real, What's Hype, and What to Build First
55% of enterprises adopted AI, but only 22% get past pilot. Learn which LLM patterns, governance frameworks, and first-90-day strategies deliver real ROI.
Filip Kralj
How can the integration of automation and agile practices revolutionize the finance and insurance sector?
Automation and Agile methods are reshaping finance and insurance, boosting efficiency, customer satisfaction, and competitive advantage.
Enno Bassen