A/B Testing That Actually Works (Most of Yours Don't)
Table of Contents+
- Why Does Statistical Significance Matter?
- What Are the Most Common A/B Testing Mistakes?
- How Do You Calculate the Right Sample Size?
- What Should You Actually Test?
- When Should You Use Multivariate Testing?
- How Do You Build a Testing Framework for Enterprise Teams?
- What Does a Mature Testing Program Produce?
- Where A/B Testing Fits in the Data-Driven UX System
- References
TL;DR
Your team ran 20 A/B tests last quarter. You declared 8 of them winners, implemented the changes, and reported a projected 15% conversion lift to leadership. Six months later, the actual conversion rate is flat. What happened?
Key Takeaways
- •Only 1 in 8 A/B tests produces statistically significant results that drive change — most enterprise testing programs are generating noise, not insights.
- •A/B tests need a minimum of 1,000 conversions per variation to reach reliable 95% statistical significance. Running tests on low-traffic pages with small effect sizes produces unreliable conclusions.
- •The 3 most common mistakes: stopping tests too early when results look promising, testing cosmetic changes instead of structural ones, and running too many variations without adjusting for multiple comparisons.
- •Companies running 12+ experiments per year see 2-3x better conversion improvements than those running fewer — velocity matters more than any single test.
- •58% of companies conduct A/B testing for CRO, making it the most popular optimization method, yet most programs fail because they lack statistical rigor and a hypothesis-driven process.
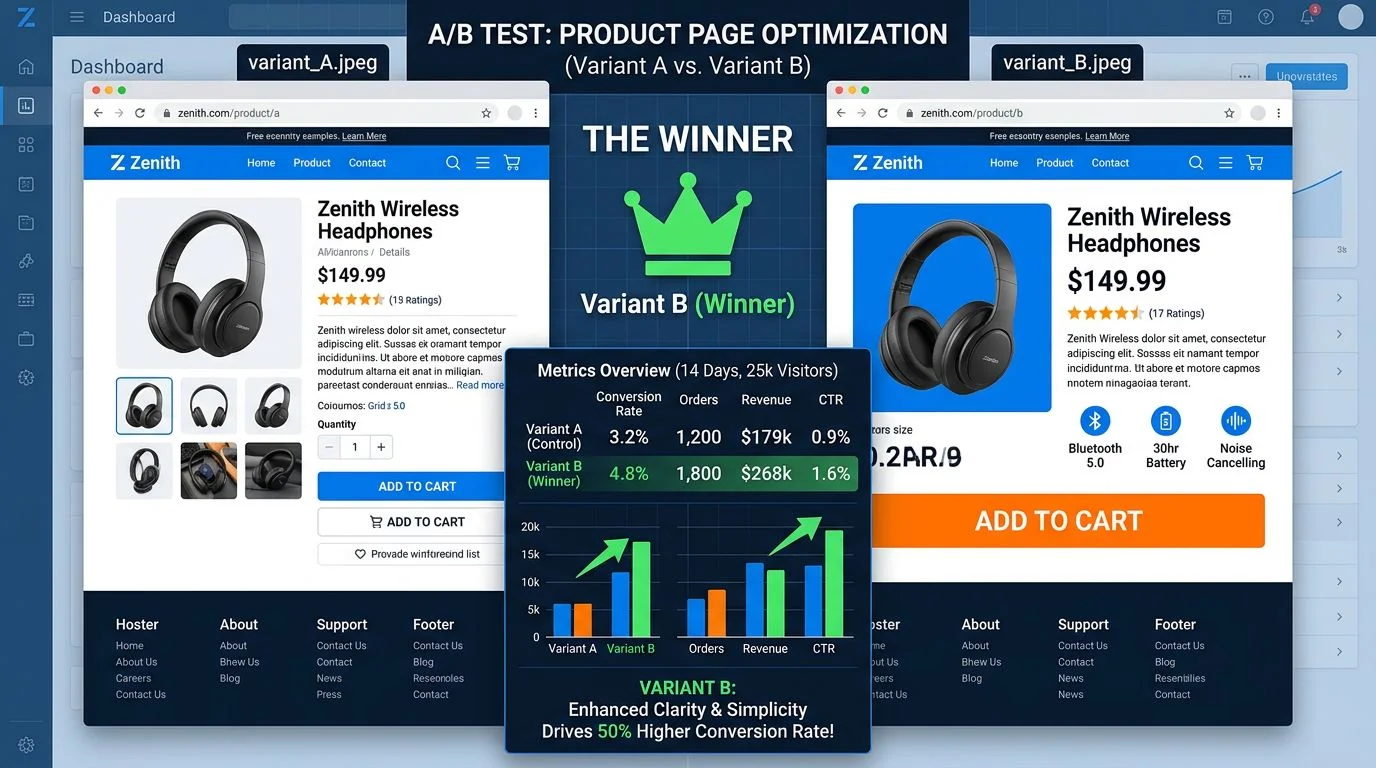
Only 1 in 8 A/B tests produces statistically significant results. Learn the math behind reliable testing, the mistakes that waste enterprise testing budgets, and a practical framework for running experiments that drive real conversion improvements.
Your team ran 20 A/B tests last quarter. You declared 8 of them winners, implemented the changes, and reported a projected 15% conversion lift to leadership. Six months later, the actual conversion rate is flat. What happened?
What happened is what happens to most enterprise A/B testing programs: the tests were not statistically valid. Results were called too early. Sample sizes were too small. The "winners" were statistical noise dressed up as insights. Only 1 in 8 A/B tests produces statistically significant results that drive change.
That means 7 out of 8 tests in a typical program are generating nothing actionable — and the ones declared as winners may be wrong.
This is not an argument against A/B testing. It is an argument for doing it correctly. Companies running 12+ experiments per year see 2-3x better conversion improvements.
The organizations that get real value from testing are the ones that understand the math, avoid the common mistakes, and build a systematic experimentation framework. Everyone else is burning budget on a science project that produces feelings instead of facts.
Why Does Statistical Significance Matter?
Statistical significance answers one question: is the difference between your control and your variation real, or could it be explained by random chance?
When you run an A/B test, you are comparing two groups of users. Group A sees the original. Group B sees the variation. If Group B converts at 4.2% and Group A converts at 3.8%, is the variation actually better?
Or did the 0.4 percentage point difference happen because Tuesday's traffic was different from Wednesday's traffic, because one group happened to include more high-intent users, or because of any other random fluctuation?
Statistical significance, typically set at 95%, means there is only a 5% probability that the observed difference is due to random chance. That 5% threshold is not arbitrary — it is the standard in both scientific research and CRO because it balances confidence with practicality.
The problem: reaching 95% significance requires volume. A/B tests need a minimum of 1,000 conversions per variation to reach reliable 95% statistical significance [1]. Not 1,000 visitors — 1,000 conversions.
If your page converts at 3%, you need approximately 33,000 visitors per variation, or 66,000 total visitors for a simple A/B test. At 1,000 daily visitors, that test needs to run for over 2 months.
Most enterprise teams don't wait 2 months. They peek at results after a week, see a promising trend, call it a winner, and move on. This is the single most common reason A/B testing programs fail.
See how we deliver AI-powered efficiency gains.
What Are the Most Common A/B Testing Mistakes?
Three mistakes account for the majority of failed testing programs. They are not technical mistakes — they are process mistakes that even experienced teams make.

Mistake 1: Stopping tests too early. This is called the "peeking problem." You check your test results on day 3 and see that the variation is outperforming the control by 12%. The p-value shows 0.04 — below the 0.05 threshold. You declare a winner.
But early test results are inherently unstable. Small sample sizes produce large swings. A test that shows a 12% lift on day 3 might show a 2% difference by day 14, once the sample size is large enough to absorb random variation.
The rule: calculate your required sample size before launching the test, and do not stop the test until you reach that sample size. No exceptions.
Mistake 1: Stopping tests too early
Mistake 2: Testing the wrong things. Button color tests are the cliché of A/B testing for a reason — they almost never produce meaningful results. Changing a button from blue to green does not address the fundamental reasons users do or do not convert.
Full-page redesigns succeed only 20% of the time, but that doesn't mean the answer is testing micro-cosmetic changes. The sweet spot is structural changes: different value propositions, different page layouts, different form structures, different content hierarchies. These changes address user behavior, not aesthetics.
Mistake 3: Running too many variations without adjusting the math. A standard A/B test compares 2 versions. When you test 4, 5, or 6 variations simultaneously (multivariate testing), the probability of a false positive increases with each additional variation. This is called the multiple comparisons problem.
Testing 5 variations at a 95% confidence level gives you a 23% chance that at least one "winner" is a false positive. If you run multivariate tests, you need to apply a statistical correction (Bonferroni or sequential testing methods) — and you need dramatically larger sample sizes.
| Test Type | Variations | Min. Conversions per Variation | False Positive Risk (uncorrected) | Best For |
|---|---|---|---|---|
| A/B test | 2 | 1,000 | 5% | High-impact structural changes |
| A/B/C test | 3 | 1,000 | 14% | Testing 2 distinct hypotheses |
| Multivariate (4+) | 4-8 | 1,000+ | 19-34% | High-traffic pages, element interactions |
| Bandit testing | 2-5 | Ongoing | Variable | Continuous optimization, limited traffic |
How Do You Calculate the Right Sample Size?
Sample size depends on 3 inputs: your baseline conversion rate, the minimum detectable effect (MDE) you care about, and your desired statistical power (typically 80%).
Baseline conversion rate. The average website conversion rate across industries is 2.35%, with the top 25% converting at 5.31% or higher [2]. Lower baseline rates require larger sample sizes because the absolute number of conversions per variation takes longer to accumulate.
Baseline conversion rate
Minimum detectable effect. This is the smallest improvement that would be meaningful to your business.
If your baseline is 3% and you are testing for a 10% relative improvement (from 3.0% to 3.3%), you need a much larger sample than if you are testing for a 30% relative improvement (from 3.0% to 3.9%).
Most enterprise teams overestimate the effect size they expect, which leads them to undersize their tests.
Statistical power. Power is the probability of detecting a real effect when one exists. At 80% power (the standard), there is a 20% chance of missing a real effect. This is an acceptable trade-off for most business contexts.
The practical math: for a page converting at 3% with a 10% relative MDE and 80% power, you need approximately 85,000 visitors per variation. For a 20% relative MDE, you need approximately 22,000 per variation. For a 50% relative MDE, you need approximately 3,500 per variation.
Run these calculations before launching any test. If the required traffic means a test will take 6 months, either find a higher-traffic page to test on, or increase the effect size by testing a more dramatic change.

What Should You Actually Test?
The highest-value tests address the biggest gaps in your conversion funnel. Start with data, not opinions.

Step 1: Identify the drop-off. Use analytics to map your conversion funnel and find where the largest percentage of users leave. 69.99% of online shopping carts are abandoned before purchase [3].
If your cart abandonment is 80%, that is where the testing opportunity lives — not on the homepage hero image.
Step 1: Identify the drop-off
Step 2: Diagnose the cause. 64% of CRO professionals use heatmaps as their primary qualitative research tool [4]. Combine heatmaps, session recordings, and user surveys to understand why users are leaving at the identified drop-off point. Is it confusion? Friction? Missing information? Lack of trust? The diagnosis determines the hypothesis.
Step 3: Form a hypothesis. A proper testing hypothesis follows this structure: "If we [change], then [metric] will [improve/decrease] because [reason based on research]." Bad hypothesis: "If we make the button bigger, more people will click it." Good hypothesis: "If we add trust signals near the checkout CTA, conversion rate will increase because 42% of users cite trust concerns as a barrier [5]."
Step 4: Prioritize by impact and effort. Not every hypothesis is worth testing. Rank hypotheses by estimated impact (based on traffic volume and expected effect size) and implementation effort. Test high-impact, low-effort hypotheses first. This is the ICE framework: Impact, Confidence, Ease.
It keeps your testing program focused on experiments that can actually move business metrics.
When Should You Use Multivariate Testing?
Multivariate testing (MVT) tests multiple elements simultaneously to understand how they interact. Instead of testing one headline change (A/B), you test 2 headlines and 2 CTA buttons in all 4 combinations (2x2 MVT).
MVT is powerful when you have enough traffic. The problem: sample size requirements multiply with each additional variable. A 2x2 MVT needs roughly 4x the traffic of a simple A/B test. A 3x3 MVT needs roughly 9x.
For most enterprise B2B sites, this makes MVT impractical on anything except the highest-traffic pages.
B2B companies see an average 2.23% website conversion rate, with top performers reaching 11.70% [6]. At a 2.23% conversion rate and 500 daily visitors, reaching 1,000 conversions per variation in a 4-variation MVT would take approximately 360 days. That is not a test — that is a geological event.
Use MVT when: your page receives 10,000+ daily visitors, you have reason to believe elements interact (header and CTA work differently depending on combination), and you can commit to running the test for the full calculated duration. In all other cases, sequential A/B tests produce faster, more reliable insights.
3x faster development with our ebiCore AI framework
Identify your top AI opportunities, validate with a PoC, and ship to production.
Start with a Strategy CallHow Do You Build a Testing Framework for Enterprise Teams?
A testing framework turns ad-hoc experimentation into a systematic growth engine. Here is a practical structure that works at enterprise scale:
Monthly test planning. Dedicate the first 2 days of each month to reviewing data, forming hypotheses, and prioritizing tests. Pull funnel data, heatmaps, session recordings, and user feedback. Generate 5-10 hypothesis statements. Rank them using the ICE framework. Select the top 2-3 for that month's testing sprint.
Monthly test planning
14-day test sprints. Align test cycles with development sprints. Each 14-day sprint includes: implementing the test variations (days 1-3), launching the test (day 4), monitoring data quality — not results (days 5-12), and analyzing results only after the predetermined sample size is reached (day 13-14).
This cadence ensures that testing is integrated into the regular development workflow, not treated as a separate initiative. 58% of companies conduct A/B testing for CRO [7], making it the most popular optimization method — but the companies that get value from it are the ones who make it a process, not a project.
Experiment documentation. Every test gets a one-page document: hypothesis, success metric, sample size requirement, test duration, results, and learnings. These documents accumulate into an organizational knowledge base that prevents teams from re-testing ideas that already failed and provides context for future hypotheses.
14-day test sprints
Quarterly reviews. Every quarter, review all tests run, their outcomes, and the cumulative conversion impact. Calculate the realized revenue impact. Present this to leadership — the business case for continued investment in testing is built on demonstrated returns, not theoretical frameworks.
"The goal is not to win individual tests. The goal is to build a system that produces reliable insights at a pace that compounds.
A testing program that runs 12 valid experiments per year will outperform a program that runs 50 invalid ones — because every insight from a valid test is a permanent improvement, while insights from invalid tests are noise that may actively make things worse."
What Does a Mature Testing Program Produce?
After 12 months of systematic testing, a well-run program typically produces:
3-5 validated, implemented improvements. Only 1 in 8 tests produces actionable results. With 12-15 tests per year, that yields 1-2 confirmed winners per quarter. Each winner is a permanent, data-validated improvement — not a guess.
A hypothesis backlog. Failed tests are not wasted tests. Each one eliminates a hypothesis and narrows the search space. After a year, you know what does not work on your site — which is as valuable as knowing what does.
Organizational capability. Teams that run tests regularly develop sharper instincts about user behavior. They ask better questions. They challenge assumptions with data instead of opinions. This capability persists even when specific team members change.
Measurable conversion lift. Companies running 12+ experiments per year see 2-3x better conversion improvements. Over a year, this compounds. A 5% lift in Q1, a 3% lift in Q2, another 4% lift in Q3 — these are not additive, they are multiplicative. The cumulative effect on revenue is substantial.
Where A/B Testing Fits in the Data-Driven UX System
A/B testing is the validation layer of a broader data-driven UX system. Research identifies opportunities. Design creates hypotheses. Testing validates — or invalidates — those hypotheses with real user behavior data. Measurement tracks the cumulative impact.
Without testing, UX improvements are opinions. With testing, they are evidence. The difference is the difference between a team that hopes their changes work and a team that knows.
The framework outlined here is not theoretical. It is the same experimentation methodology we apply across 100+ projects in 14-day sprint cycles. Research, hypothesis, test, measure, iterate.
If your current A/B testing program is producing inconclusive results and you want to rebuild it on solid statistical foundations, explore our UX Growth services.
References
- [1] VWO, "A/B Testing Sample Size" — A/B tests need a minimum of 1,000 conversions p Source
- [2] WordStream — The average website conversion rate across industries is 2. Source
- [3] Baymard Institute — 69. Source
- [4] Hotjar, "Conversion Rate Optimization" — 64% of CRO professionals use heatmaps a Source
- [5] Econsultancy, "Conversion Rate Optimization Report" — Adding trust signals near Source
- [6] WordStream — B2B companies see an average 2. Source
- [7] Econsultancy / Adobe, "Digital Trends" — 58% of companies conduct A/B testing fo Source
Explore Other Topics
Ready to unlock AI-driven efficiency?
30-minute call with an engineering lead. No sales pitch - just honest answers about your project.
98% engineer retention · 14-day delivery sprints · No lock-in contracts
Related Reading

Automated QA: How AI Changes the Economics of Testing
AI-powered QA reduces manual test writing by 60% and cuts testing cycles from weeks to hours. Learn how AI test generation, visual regression testing, and flaky test detection transform testing economics.
Filip Kralj
How REWE Runs Multi-Country E-Commerce on 14-Day Sprint Cycles
How enterprise retailers like REWE ship e-commerce features every 14 days. The sprint delivery model, team structure, and QA gates.
Enno Bassen
How Much Does a Shopware Enterprise Build Cost in 2026?
Shopware enterprise builds cost EUR 30K to 500K+ in 2026. Transparent breakdown of cost tiers, hidden fees, and what drives budget overruns in DACH.
Enno Bassen